Extracting Bitmap From Plan 9 Fonts
Update 2022.7.17: To turn a font (e.g.
.ttf) into Plan9 subfonts you need to:
- Generate bitmap for all the characters in this font
- Convert the bitmap into subfont files
- Generate an
.fontindex file - or not, you can directly insert them into existing indices as well.To combine two (or more) plan9 subfonts which shares the same range you have to:
- retreve the bitmaps from all the subfonts;
- somehow slice them together into one single bitmap;
- convert this bitmap into a new subfont file.
For example, assume font A has
0x2000,0x2002,...,0x2008and font B has0x2001,0x2003,...,0x2009. Normally the subfont of A will only contain the glyphs for 0x2000, 0x2002, etc. and the subfont for B will only contain the glyphs for 0x2001, 0x2003, etc.. In this case, if both subfonts are used for the range0x2000~0x2009in their respective.fontfile, directly replacing this entry in.fontof A will add the glyphs from B but remove the glyphs from A. To actually make use of both sets of glyphs, you can either:
- Manually specify the range like this:
0x2000 0x2000 A.subfont 0x2001 0x2001 B.subfont 0x2002 0x2002 A.subfont 0x2003 0x2003 B.subfont # ...which may or may not be a hassle, or:
- Combine the two subfont into one and use the new subfont.
This has been on my todo list for almost a year. I wanted to do this because this gb/ font (noted "script fonts?" on the wiki page) is (1) actually simplified Chinese fonts that supports the GB2312 standard (probably the reason for the folder name gb) and (2) it's quite an old font. I've only seen it once *ages* ago used by a weird-ass text editor with built-in special input method. I have absolute zero idea how the font got into Plan 9 (if you know this please let me know).
I thought this is gonna take days because I need to painfully read through pure *nix-flavour (?) manual pages, turns out it can be done in one afternoon. Why the heck did I keep this on my todo list for this long..??.?
The font files can be found here. Here is a part of the bitmap I've extracted:
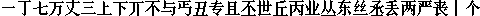
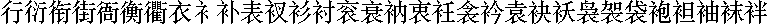
The format of Plan 9 font files
A "font" in plan9 is made up of many "subfont" because:
A Font may contain too many characters to hold in memory simultaneously.
A subfont file contains the bitmap data for a range of Unicode codepoints. Its file name specifies the range or the start of the range. For example the first row of the bitmap above comes from the file named The range is specified by the Song.4e00.16, which means this file contains the data of U+4E00~ for the 16px size Song font..font index files.
A subfont file is made up of three parts:
- An image containing character glyphs;
- A subfont header, which contains three 12-byte strings specifying the value for 3 integers called
n,heightandascend. The baseline of the font would beascendrows from the top of the image. - A character information list for this particular subfont file. It contains
n+16-byte entries. Each entry is made up of:- A 16-bit integer
xin little-endian; - Four 8-bit integer called
top,bottom,leftandwidthrespectively.
- A 16-bit integer
When displaying the bitmap for the character c at point p:
- The data is retrieved from the subfont file. If
ipoints to the character information forcandi+1points to the character information for the next character afterc, then the bitmap data forcis extracted from(i->x, i->top)to((i+1)->x, i->bottom).i->widthis not used when executing this step. - The data would be displayed at
(p.x + i->left, p.y), and the next character (if there's any) would be displayed at(p.x + i->width, p.y)
The format of the image in plan9 containing the glyphs (described in image(6)) is described as follows:
- An image can be compressed or uncompressed. All compressed image starts with the string
"compressed\n". - An image has an image header. In an uncompressed image this header would be at the start of the image data; if the image is compressed it's after the string
"compressed\n". It contains five 12-byte strings:chan: this field denotes the color information and bit depth of the image. Because we're dealing with font files here this field would bek1, which means 1-bit grayscale with each bytes denotes 8 pixels.r.min.x: the minimal validxvalue for this image.r.min.y: the minimal validyvalue for this image.r.max.x: the maximum validxvalue plus 1.r.max.y: the maximum validyvalue plus 1.
Thus:
- the width and height of the image would be
r.max.x-r.min.xandr.max.y-r.min.yrespectively; - the valid range for
xis[0, r.max.x-1]; - the valid range for
yis[0, r.max.y-1];
- Right after the image header is the actual pixel data. These data are stored in rows. If the image is compressed, it's contained within a list of compression blocks. These blocks has a maximum length because it's designed to be easily sent through the 9P protocol bit by bit. Each compression block contains:
- A block header, containing two 12-byte strings of numbers.
- The first number is the y coordinate of the last row in this block plus 1.
- The second number is the length of the compressed image data in this block.
- The compressed image data, which is a list of variable-length code words.
- A block header, containing two 12-byte strings of numbers.
The decompression of the blocks goes as follows.
- Each code word denotes a piece of uncompressed data or a copy command that copies a part of the already decompressed data and attaches it at the end.
- If the first byte of the code word is with its high-order bit set (i.e. not smaller than 128/0x80), then this code word denotes uncompressed data. This byte with its high-order bit set to zero (i.e. minus 128) indicates the length of this piece of data, values from 0 to 127 encode lengths from 1 to 128 bytes. The data is right after this first byte.
- e.g. if the first byte is
10001100, then length field would be0001100which is 12; 12 indicates there's 12+1=13 bytes of data. Thus the next 13 bytes should be concatenated to the end of the currently decompressed data.
- e.g. if the first byte is
- If the first byte of the code word is with its high-order bit unset (i.e. smaller than 128/0x80), then it's a copy command. Copy command spans 2 bytes. Bit 6 to bit 2 of the first byte is the copy length field, values from 0 to 31 denotes a copy length of 3 to 34 bytes. Bit 1 & 0 of the first byte, together with the second byte, is the copy offset field; the offset is counted backwards from the end of the currently decompressed image data; values from 0 to 1023 denotes an offset of 1 to 1024 bytes.
- e.g. if the first byte is
00000100and the second byte00010001, then:- the copy length field would be
00001=1, which denotes a copy length of 4 bytes; - the copy offset field would be
00 00010001=17, which denotes a copy offset of 18 bytes; - so we start counting backwards from the end of the decompressed data and copy 4 bytes from there. In python this would be something like
decompressed += decompressed[-18:-18+4].
Fig. 1: Formats of code word

Fig. 2: Example of handling code words (1)
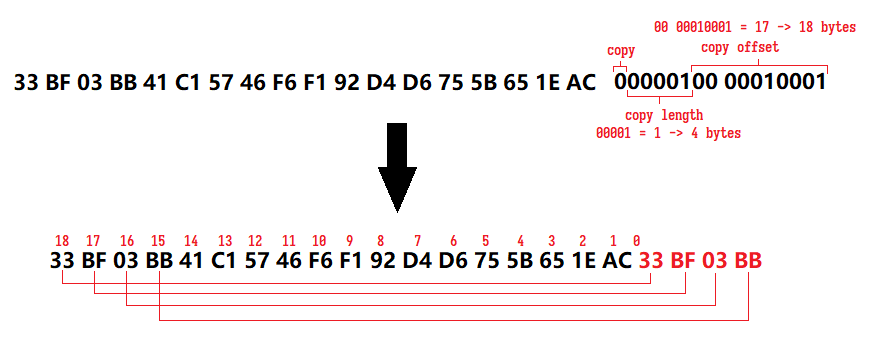
Fig. 3: Example of handling code words (2)
- the copy length field would be
- e.g. if the first byte is
With all this knowledge we can finally write the code:
import sys
def main(filename):
with open(filename, 'rb') as f:
s = f.read()
if s.startswith(b'compressed\n'):
print('compressed.')
s = s[len(b'compressed\n'):]
compressed = True
else:
print('not compressed.')
compressed = False
header1 = s[:12*5].decode('utf-8')
s = s[12*5:]
print('chan', header1[:12])
print('r.min.x', header1[12:24])
print('r.min.y', header1[24:36])
print('r.max.x', header1[36:48])
print('r.max.y', header1[48:])
rminy = int(header1[24:36].strip())
rmaxx = int(header1[36:48].strip())
rmaxy = int(header1[48:].strip())
if compressed:
miny = rminy
code_word_list = []
# for each block:
while miny < rmaxy:
raw_block_header = s[:2*12]; s = s[2*12:]
maxy = int(raw_block_header[:12].decode('utf-8'))
nb = int(raw_block_header[12:].decode('utf-8'))
# extract code words from block
raw_block_data = s[:nb]; s = s[nb:]
i = 0
raw_block_data_len = len(raw_block_data)
while i < raw_block_data_len:
if raw_block_data[i] >= 128:
this_word_len = raw_block_data[i] - 128+1
i += 1
code_word_list.append(raw_block_data[i:i+this_word_len])
i += this_word_len
else:
a = (raw_block_data[i]&0b01111100)>>2
b = ((raw_block_data[i]&0b00000011)<<8)|(raw_block_data[i+1])
code_word_list.append((a, b))
i += 2
miny = maxy
# decompress from code words
res = b''
i = 0
for code_word in code_word_list:
if type(code_word) is bytes:
res += code_word
i += len(code_word)
else:
a, b = code_word
lenx = a+3
off = b+1
for _ in range(lenx):
res += bytes([res[-off]])
i += 1
with open(f'{filename}.pbm', 'w') as f:
print(f'P1\n{rmaxx} {rmaxy}', file=f)
for k in res:
z = f'{k:08b}'
for zz in z:
print(zz, ' ', sep='', end='', file=f)
n = int(s[:12].decode('utf-8'))
height = int(s[12:24].decode('utf-8'))
ascent = int(s[24:36].decode('utf-8'))
s = s[36:]
info_list = []
for _ in range(n+1):
raw_info = s[:6]
x = raw_info[0]|(raw_info[1]<<8)
top = raw_info[2]
bottom = raw_info[3]
left = raw_info[4]
width = raw_info[5]
info_list.append((x, top, bottom, left, width))
s = s[6:]
with open(f'{filename}.info.txt', 'w') as f:
print(f'n={n}, height={height}, ascent={ascent}', file=f)
for x, top, bottom, left, width in info_list:
print(f'x={x}, top={top}, bottom={bottom}, left={left}, width={width}', file=f)
if __name__ == '__main__':
main(sys.argv[1])
Maybe one day I'll learn how TrueType works and compile a .ttf out of this... There's surprisingly quite a lot of stuff to learn.